随着AI应用在企业中的普及,不少企业在数据治理方面都有一个单纯且直接的需求,就是我们能不能把企业的所有信息都变成AI的知识库,这样AI就能学习和分析这些信息,从而结构化管理并有效利用,提供企业员工和管理层各种信息查询功能及决策依据。
AI知识库变成了企业记忆或者企业大脑般的存在。
所以,把企业现有的数据和未来不断产生的数据结构化、知识库化成为企业AI有效落地的第一步。
在这个需求下,不少企业开始尝试搭建自己的AI知识库,一般采用的方式是直接把非结构化数据(文件、图片)向量化,然后分片入库,利用RAG技术进行查询,然后把查询到的分片结果注入prompt。但结果往往差强人意,一般出现的问题为:
- 准确性很差。AI返回的回答和数据特别是统计类的数据准确性差。
- 回答一致性差。同一个问题问几次,AI的回答的差别很大。
- 命中差。一些文档里明确的知识点在输出结果的时候不能体现,感觉像没入库。
- 关联度差。关联知识内容没有体现,譬如写糖尿病软文,目标想带出关联的产品,但关联不到。
- 幻觉明显。大模型倾向于胡说八道。
- 入库效率极低。一个几百页文档入库要跑几小时
这一系列问题造成企业构建AI知识库的困难重重,但无论是调分片大小还是引入知识图谱或者增加检索数量甚至引入深度搜索扩写问题,还是替换前端大模型,效果都很难提升。
这时候往往让人产生一种错觉,是目前AI还不堪此任么?
显然不是,因为各行业已经有不少企业成功落地AI,并且在生产环境取得了显著的成绩。根据硅谷财富管理公司Iconiq Capital发布的深度AI行业报告《The Builders Playbook 2025》的调查,知识库应用已经是AI应用里排名前三的应用,前面两个是AI编程和AI文章撰写。
所以,是方法或者对AI知识库构建的理解错了!
下面是根据我们3年来在多个行业进行非结构化信息管理入库的粗浅经验总结的一些方法论,分享给大家:
先讲几个逻辑:
目前还不存在一个通用型知识库系统或者知识库构建模式直接拿来用就能达到相当完美的效果,但对于一般企业使用场景来说,能做到一个相对效果较好的知识库还是够用了。
因为不同的行业对不同数据的提取要求和重要程度划分是不一样的,如果知识库要做到很好的效果,是需要根据行业的数据特性和应用场景进行结合的,譬如:法务合同关注的是法务风险点的提取;标书稽核关注的废标的点和分数的计算;报关文件关注的是各种采购单据和资质的审核。
所以我们需要为不同的场景设计好不同的schema——这是提示词工程的重要一环。 泛化性好,部署周期短。 虽然不需要单独训练模型,但需要行业专家和开发运维团队合作设计schema——这是技术层面上绕不开的。
不过,大多数知识库效果不好的原因可能还没有到这个深度,我们接触了不少AI知识库案例,很多知识库效果不好的原因往往是:
从入库环节就错了!
其实,知识库效果好不好,信息入库质量至少占80%,只要入库信息分片合理,覆盖全面,效果都不会太差,
要做好知识库,先做好入库流程!入库做好了,就成功至少一半。
内怎样的入库才是比较“靠谱”的做法呢?
以我们的产品巴别鸟企业网盘为例,我们一共有三种知识库入库方式。其中公有云SAAS服务版本,因为要处理大量客户的大量数据,为了节约算力成本,我们采用了最简单的损耗算力最小的向量化入库方式,这样能保证用户上传的文件都自动快速入库,从而为用户提供最基础的知识库服务。
私有部署用户一般有自己的算力服务器,并且数据量相对SAAS版本小不少,这个时候我们就可以以时间换质量,采用更加精细但更消耗算力(但质量好不少)的入库方式。
这篇文章主要以我们私有云产品的智巢AI知识库为例,详细介绍一下我们采用的入库方式和策略,算是抛砖引玉,希望能给正在搭建知识库的你一点启发。
巴别鸟智巢AI(私有部署版本)面对不同的用户需求和场景有两种入库方式,并且也支持两种入库方式的混用。
先讲原理,传统的入库解析(譬如 tika)只解析了文档的纯文字的内容,或者OCR之后的纯文字的内容,丢失了大量的信息,这会导致:
– 页面的布局信息丢了,后果严重,甚至会导致抽取出来的文字阅读顺序是错的。
– 表格信息不完整,甚至是错误的。
– 图片的信息不完整,无法与文字相关联。
-只能支持纯文本的文件,如:world、excel、TXT、markdown这些,对图文并茂并且有版式的复杂word、pdf、ppt、图片、甚至网页等结构的文件可以说无能为力。
但我们生产活动中的大量文件,譬如图纸、说明书、演示PPT、PDF扫描件、发票、报表…都是有结构甚至图文并茂的,知识库要有用首先这些文件也需要入库。
为了解决上面的这些问题,我们必须要对文档做深度的解析,目前在工业界有两种常见的解决方案:
1. 基于pipeline(速度很快,精度较高)GPU耗费低
页面布局分析(将页面分割成可独立ocr的分块) —->分块内部 OCR —->图、文、表格、公式的提取
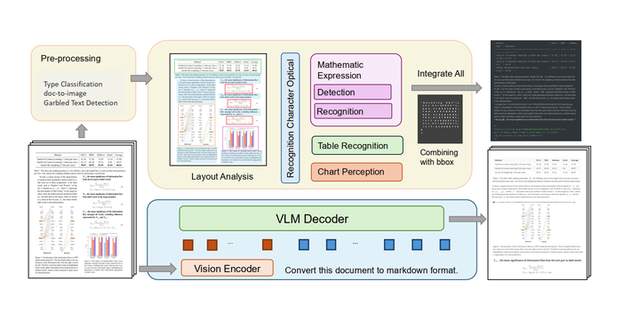
2. end-to-to(端到端) vlm (速度较慢,精度很高)GPU耗费高
训练一个解析模型,一次性把上面的pipeline的事情全做了。
pipeline方式,速度大概是0.1秒/页
vlm方式,速度大概是5秒/页
这就是巴别鸟主要采用的两种入库方式,对于大多数用户,基于pipeline的方式已经完全够用了,并且能节约大量算力,显著提高入库速度。譬如:输出一个图文并茂的操作指南、或者统计发票信息。但对于一些有行业特殊需求并且对准确度要求较高的用户,我们会根据用户的需求场景选用VLM方式。
首先,我们来讲讲pipeline方式的具体流程和细节
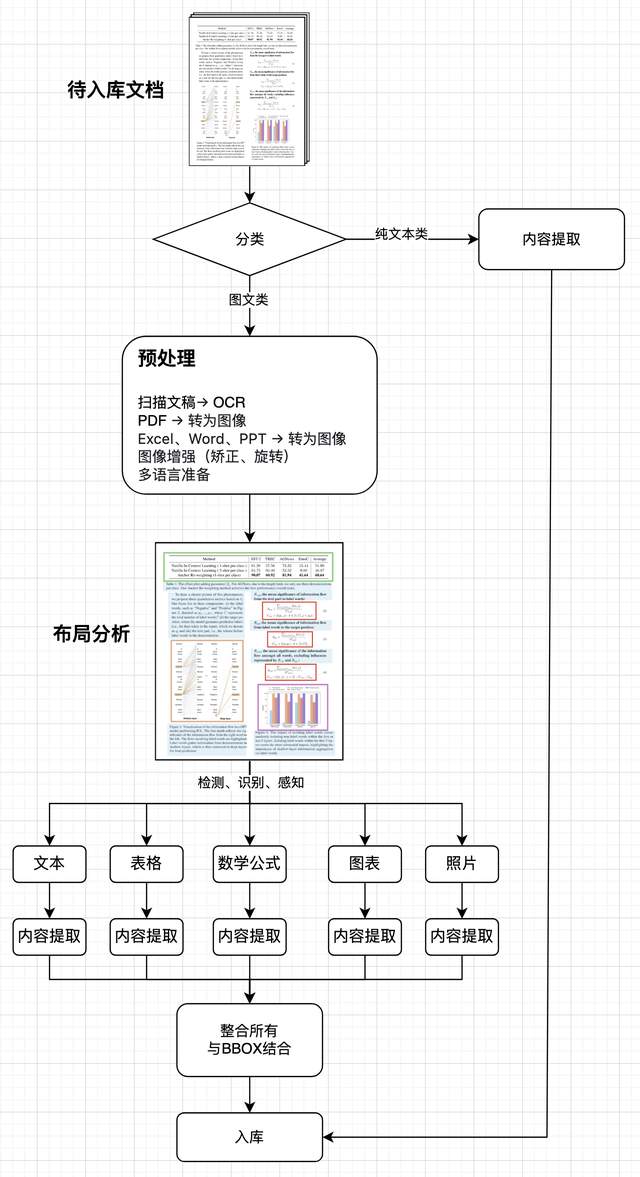
巴别鸟智巢AI知识库pipeline入库流程
基于pipeline的知识库入库
第一步:文档预处理
- 目标:统一格式、提升可解析性
- 操作:
- 扫描文档 → OCR(如Tesseract、PaddleOCR)
- PDF → 图像(如PDF转PNG)
- 图像增强(去噪、旋转校正)
- 多语言识别准备(如中英混排)
说白了就是判断文件的构成,譬如图文混排的文档、或者图片、或者PDF这类有版式的文件和仅仅是文本的文件分开。有版式的文件全部转成图片。
第二步:布局分析(Layout Analysis)
- 目标:识别文档结构(段落、标题、表格、图表、公式等)
- 推荐模型:这里有很多种解析模型可以推荐,当然也支持根据不同场景需求的混用。
- DiT(Document Image Transformer)
- LayoutLMv3(融合文本+布局+图像)
- DocLayout-YOLO(快速检测复杂布局)
- 输出:每个区域的边界框(bbox)+ 类别标签(如标题、正文、图表)
分析图片文件,把布局、版式、结构分拆成各类元素,如:表格、公式、文本、图像….
第三步:内容提取(Content Extraction)
按元素类型分别处理提取内容:
不同类型的元素使用不同的小模型进行内容提取
第四步:语义理解与结构化(Semantic Structuring)
把提取的内容结构化并建立关联
- 目标:将提取内容转化为知识图谱或向量数据库可用格式
- 操作:
- 使用LayoutLLM或DocLLM理解语义角色(如“方法”、“结论”、“定义”)
- 对段落打标签(如“背景”、“实验”、“引用”)
- 提取实体与关系(如“作者-机构”、“公式-变量”、“图表-数据”)
第五步:数据清洗与标准化
- 去重:基于标题+摘要+作者去重
- 标准化:
- 统一单位(如“ml” vs “mL”)
- 统一公式格式(如\frac{a}{b} vs a/b)
- 统一图表单位(如“k” vs “千”)
第六步:向量化与索引(Vectorization & Indexing)
- 向量化模型:
- 文本:BERT、E5、BGE
- 图表/公式:ChartX、UniMERNet编码器
- 多模态:InternVL、Qwen-VL
- 索引方式:
- 稠密向量:FAISS / Milvus
- 稀疏向量:BM25(用于关键词检索)
- 混合检索:RAG系统中结合两者
第七步 入库与版本管理
向量化的数据以jaon的形式进行入库,这里还有个重要的环节就是版本管理,巴别鸟网盘本身具有版本管理功能,更新的文档内容同时也会按版本更新知识库。
第八步质量评估与反馈闭环
这是一个很容易被忽视的环节,但只有建立良好的反馈闭环和质量评估体系才能对知识库内容质量有一个客观评估,体系化的迭代和优化知识库的质量。
- 自动评估指标:
- OCR:CER(字符错误率)
- 表格:TEDS(结构相似度)
- 公式:ExpRate(完全匹配率)
- 人工抽检:每月抽检5%入库内容
- 用户反馈:集成“纠错”按钮,收集用户修正数据用于微调模型

推荐的工具(开源)
基于VLM的知识库入库
VLM入库基于当前主流VLM(视觉-语言大模型)架构(如LLaVA、InternVL、Nougat、SmolDocling等),结合生产级RAG系统实践,VLM方案的知识库入库流程可总结为端到端入库,跳过传统OCR+模块拼接,直接由VLM一次性完成“图像→结构化知识”的转换。
说白了就是利用一个专用的VLM模型,把预处理后的文档直接入库。
VLM入库流程:
关键细节说明
那么,pipeline方式和VLM方式对比有什么优缺点?企业在搭建知识库的时候选择什么方式更适合呢?
最直观的是算力需求和入库效率,pipeline方式CPU和GPU都可以利用,同样的文档入库效率能比VLM高50倍。VLM对GPU要求比较高,入库效率较低,但总体质量更好些。
Pipeline vs VLM:优缺点对比
实际应用场景中,我们可以根据应用场景、知识库的规模、硬件投入… 等因素选择使用什么入库方式,也可以多种入库方式混用,适合的就是最好的。
当然,你也可以购买现成的巴别鸟企业网盘智巢AI知识库,我们提供从企业网盘到AI知识库到AI应用落地的一揽子标准产品解决方案,同时我们也支持正对特定行业场景的知识库优化及定制开发。
访问我们的官网,注册巴别鸟企业网盘即可试用。
注:巴别鸟公有云SAAS版本为了节约算力资源仅做了文档级 Embedding + 向量检索。