越来越多的企业开始使用AI来搭建知识库、优化生产流程、使用各类AI智能体 ,考虑到数据安全可控和数据本地化监管要求,不少企业需要本地化部署AI算力服务器。
那么问题来了,算力服务价格从十几万到几百万不等,开源模型可选参数这么多,AI发展又快,要选择什么样的算力服务器才适合自己企业的生产环境呢?
自从我们的产品巴别鸟企业网盘推出智巢AI服务以来,我们的私有化客户都会提出这个问题,这个问题还有几个衍生问题,总结出来为:
- 私有化AI算力服务器能不能达到公网大模型的效果?如果达不到差别有多大?
- 如果投入很大会不会算力跑不满很浪费?如果买很基础的,会不会很慢并且效果也不好?
- 有没有什么性价比高的可拓展方案?(预算不足怎么办?)
所以,这篇文章回答的就是这几个问题,给用户一个可参照的配置指南。
该配置指南主要以推理运算为主,不适用于有大模型训练要求的用户。
首先回答第一个问题:
私有化AI算力服务器能不能达到公网大模型的效果?如果达不到差别有多大?
公网服务对接的大模型可选范围是比较广的,甚至可以根据不同的需求选择相对擅长的模型,譬如深度思考用DeepSeek、语义理解用智谱、写文章用kimi…并且公网接口的大模型一般也都是全血大模型,拿Deepseek 推理模型举例,公网接入的一般都是DeepSeek R1 671B全血。
私有部署如果用671B 全血就要购买很贵的算力服务器,一般考虑成本会采用 32B参数的蒸馏模型。32B的模型因为参数量限制效果是肯定不如671B的,那么差距有多大?
这个问题可以简化为: DeepSeek-R1 671B 和 32B 的差距有多大?
这里先明确个概念,DeepSeek R1 32B 版本指的是 “
DeepSeek-R1-distill-Qwen-32B” 版本,是使用 DeepSeek R1 Zero 和DeepSeek V3得到的高质量强化训练数据对 Qwen-32B 版本进行SFT(监督微调)后得到的模型,本质上是Qwen大模型,而不是DeepSeek大模型。QWQ 32B出来后,因为效果比R1 32B好不少,所以下文图表比较的是 DeepSeek-R1 671B 和QWQ 32B
先说结论:在一般企业场景使用上差别并不大。特别是在中文和英文环境上。
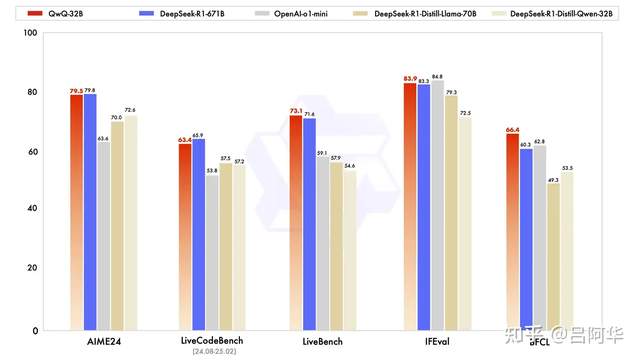
QwQ-32B基准测试结果
是不是有点反常识,参数小不少,性能差不多。当然,这还使用场景有关,32B版本在很多方面有局限性:

Qwen官方指出的局限性
官方测试结论也显示,32B的DeepSeek-R1大约能够实现90%的671B的性能,且在AIME 2024、GPQA Daimond、MATH-500等部分场景之下效果略优于OpenAI的o1-mini。
在我们的部署经验中,蒸馏32B模型对小语种的支持很差,但是中文和英文的日常应用还是没有问题的。
但是低于32B(如:7B、8B、14B)的模型差异还是比较明显的,所以我们推荐用户部署32B的模型。
这里说的是深度思考模型,一般我们还需要部署一个non-thinking模型来高效处理非深度思考的场景。
开源模型也在不断发展,截止2025年9月 我们推荐的模型为:
所以,如果企业没有特殊要求,部署两个32B级别的模型就够用了。没有必要部署671B的全血模型。
接下来回答第二个问题,购买什么样的算力服务器合适?
我们的答案是,按需购买即可。刚开始买能满足当下需求最基础的算力服务器。随着业务增长需要更大的算力时,再进行扩展。首先算力服务器长远上看是会越来越便宜的,其次,算力服务器是可以叠加多台使用的。
我们可以根据选用的模型和并发量粗略预估下所需算力
首先以FP8精度部署32B模型所需的显存是32-48G,所以推荐使用48G的显卡,下面是各显卡按FP8精度部署deepseek 32B的每秒并发token数(考虑用户体验,保守估算,不用极限并发):
注:A6000 没有 FP8 Tensor-Core,只能用 FP16 跑,算力 309 TFLOPS,带宽也最低,因此 32B 模型即使放得下,吞吐只有 Ada 架构的 40 % 左右。所以不推荐A6000,可以选用 6000 Ada作为替代。
我们可以把token数简单理解为模型每秒产生多少字符,一般使用大模型时单用户每秒有20个tokens就能感觉比较流畅了,100并发tokens相当于可以5个用户同时使用也不觉得卡顿,要增加并发数就增加算卡的数量,而且算卡多了还会有一定的增益。
譬如:4*4090 48G 理论上就可以做到 1200 tokens/s 的并发tokens(保证单用户体验的前提下)
所以我们可以根据使用的用户并发数来计算需要的算卡数量,考虑到我们需要跑两个30B量级的大模型,所以需要至少2块48G显存的算卡。(Qwen3-30B-A3B 有融合模型方案,但是出于性能考虑不推荐)
如果是信创环境部署,推荐使用华为Atlas 300I Duo(双昇腾 310P SoC,一体封装,共享 96 GB LPDDR4X,带宽 408 GB/s)显卡,这样1块卡可以部署2个32B大模型在上面还绰绰有余,甚至向量服务也可以跑在上面。不过价格也贵不少。
同时,我们还需要至少一块24GB的显存算卡来做向量和知识库入库(如果采用VLM方案)。
这里有两个方案可以选,一个是部署一台专用的向量服务器(使用一块3090 24G) ,一个是再增加1-2块算卡,增加的算卡不仅可以跑向量,也可以增加每秒输出的Tokens数量。
然后从性价比角度来看,选择就简单了,显卡的价格一列就明了。
如果只考虑性能,肯定是 4090 48G 的方案最划算,但4090 48G并不是官方版本而是魔改版本,稳定性和保修问题都需要考虑,同时4090的功耗高达450w,比5880ada和6000ada的250w功耗高不少,功耗高意味着需要强大的散热。
考虑性能和极致性价比选用 4090 48G,考虑稳定选用 5880ada 48G,不缺预算考虑 6000ada 48G,信创就用Atlas 300I Duo
下面是我们推荐的企业上AI的基础配置,这个配置能兼顾向量和2个32B大模型在FP8精度的运行,保证AI输出效果,并且能支持10-20个用户并发流畅使用。如果对大模型的流畅度没有极高要求,能支持到最高100并发。
推荐配置一:算力服务器和向量服务器分开,双服务器方案(低预算高性价比)
总价:13W 左右,如果算力服务器 选用 2块 6000ADA 总价在16W左右,如果算力服务器选用2块4090 48G,总价在9万左右。配合优化大概能做到并发 500-1000 tokens/s
推荐配置二:单台算力服务器方案
总价:20W左右,如果算力服务器选用 4块 6000ADA,总价在30W左右
但这个价位拥有更强大的算力,即使安装了向量服务器,大模型token性能也比上个方案大2倍。配合优化 4块 6000ADA大概能做到并发1500-2000 tokens/s
推荐配置三:信创服务器方案
总价:18W左右,能做到并发 1500-2000 tokens/s
巴别鸟企业网盘私有化提供了从网盘部署到大模型私有化部署+AI知识库等一系列解决方案及服务,帮助企业更好的落地AI。
欢迎访问我们官网试用巴别鸟智巢AI网盘,注册企业公有云版本即可。